Jump To OS : Thread
OS 2탄이 돌아왔습니다! 하하.. 하나의 포스트로 정리하려고 했는데 역시나 OS는 넓고 어렵습니다 ㅠㅠ 이번에는 Thread입니다.
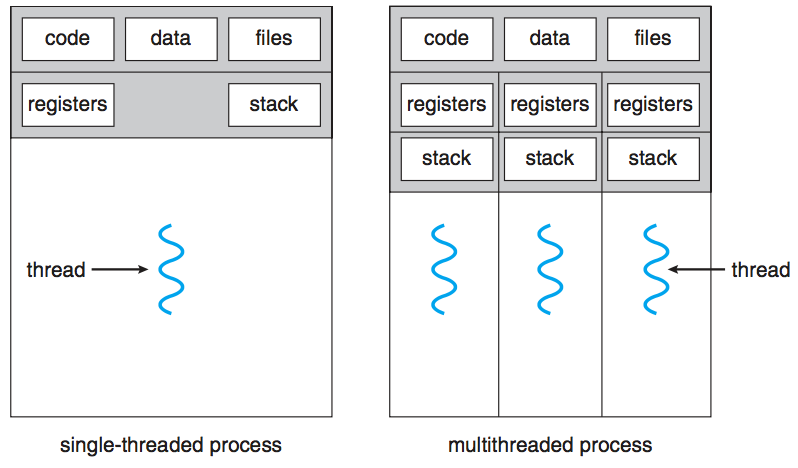
스레드는 CPU 사용의 기본 단위다. 스레드 ID, 프로그램 카운터, 레지스터 세트 및 스택을 포함한다.
Motivation
단일 응용 프로그램이 여러 가지 유사한 task를 수행해야 할 수도 있다. 예를 들어, 웹 서버는 웹 페이지, 이미지, 사운드 등에 대한 클라이언트 요청을 받아들인다. 사용량이 많은 웹 서버에는 여러 클라이언트가 동시에 액세스 할 수 있다. 웹 서버가 기존의 single thread process로 실행되면 한 번에 하나의 클라이언트만 서비스 할 수 있으며 클라이언트는 요청을 처리하는 데 오랜 시간을 기다려야 할 수 있다. 한 가지 해결책은 서버가 요청을 각각의 single process로 실행되도록하는 것이다. 서버가 요청을 수신하면 서버는 해당 요청을 처리 할 별도의 process를 쓴다. 그러나 process 생성은 많은 시간과 자원을 필요로 한다.
Benefits
- Responsiveness. 쌍방향 응용 프로그램의 다중 스레드는 프로그램은 작업의 일부가 차단되거나 긴 작업을 수행하는 경우에도 프로그램이 계속 실행되도록하여 사용자의 입력에 대한 응답 속도를 높인다. 특히 사용자 인터페이스 설계에 유용하다. 예를 들어 사용자가 시간이 많이 걸리는 작업을 수행하는 버튼을 클릭하면 단일 스레드 응용 프로그램은 작업이 완료 될 때까지 사용자에게 응답하지 않는다. 반대로 시간이 많이 걸리는 작업이 별도의 스레드에서 수행되는 경우 응용 프로그램은 사용자에게 응답한다.
- Resource sharing. 프로세스는 Shared Memory 및 Message passing과 같은 기술을 통해서만 리소스를 공유 할 수 있다. 이러한 기술은 프로그래머가 명시적으로 구성(하드코딩)해야한다. 그러나 스레드는 메모리와 기본적으로 속한 프로세스의 리소스를 공유한다.
- Economy. 프로세스 생성을 위해 메모리와 리소스를 할당하는 것은 많은 비용이 든다. 스레드는 스레드가 속한 프로세스의 리소스를 공유하기 때문에 스레드를 만들고 context-switch 하는 것이 더 경제적이다. 오버 헤드의 차이를 경험적으로 측정하는 것은 어려울 수 있지만 일반적으로 스레드보다 프로세스를 만들고 관리하는 데 훨씬 많은 시간이 소요된다. 예를 들어 솔라리스에서 프로세스 생성은 스레드를 만드는 것보다 약 30 배 느리고 context-switch은 약 5 배 느리다.
- Scalability. 스레드가 다른 프로세싱 코어에서 병렬로 실행될 수 있는 멀티 프로세서 아키텍처에서는 멀티 스레딩의 이점을 훨씬 크게 누릴 수 있습니다. 단일 스레드 프로세스는 사용 가능한 프로세서 수에 관계없이 하나의 프로세서에서만 실행될 수 있습니다.
Multicore Programming
코어들(2개이상)이 CPU 칩 전체 또는 CPU 칩 안에서 존재하면 멀티 코어 또는 멀티 프로세서 시스템이라고 한다.

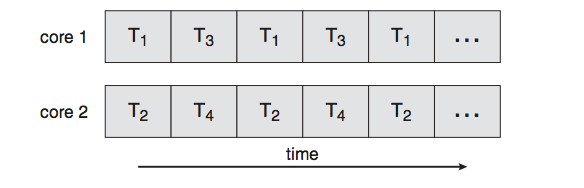
동시성은 싱글 코어에서 멀티 스레드를 동작시키기 위한 방식으로 멀티 태스킹을 위해 여러 개의 스레드가 번갈아가면서 실행되는 성질을 말한다. 동시성을 이용한 싱글 코어의 멀티 태스킹은 각 스레드들이 병렬적으로 실행되는 것처럼 보이지만 사실은 번갈아가면서 조금씩 실행되고 있는 것이다. 병렬성은 멀티 코어에서 멀티 스레드를 동작시키는 방식으로, 한 개 이상의 스레드를 포함하는 각 코어들이 동시에 실행되는 성질을 말한다. 따라서 병렬 처리없이 동시성을 가질 수 있다.
Type of Parallelism
일반적으로 병렬 처리에는 데이터 병렬 처리와 작업 병렬 처리의 두 가지 유형이 있다. 데이터 병렬 처리는 전체 데이터를 쪼개 서브 데이터들로 만든 뒤, 서브 데이터들을 병렬 처리하여 작업을 빠르게 수행하는 것을 말한다. 자바 8에서 지원하는 병렬 스트림이 데이터 병렬성을 구현한 것이다. 서브 데이터는 멀티 코어의 수만큼 쪼개어 각각의 데이터들을 분리된 스레드에서 병렬 처리한다. 작업 병렬 처리는 서로 다른 작업을 병렬 처리하는 것을 말한다. 대표적인 예는 웹 서버로, 각각의 브라우저에서 요청한 내용을 개별 스레드에서 병렬로 처리한다. 기본적으로 데이터 병렬 처리는 여러 코어에서의 데이터 배포와 여러 코어에서의 작업 분산에 대한 작업 병렬 처리를 포함한다. 대부분의 경우 응용 프로그램은 이 두 가지 전략을 섞어서 사용한다.
Multithreading Models
스레드에 대한 지원은 사용자 수준에서의 user thread 또는 커널에 의해 제공되는 kernel thread을 제공받을 수 있다. 사용자 스레드는 커널 위에서 작동하고 커널 지원없이 관리되며 커널 스레드는 운영 체제에서 직접 지원 및 관리된다.
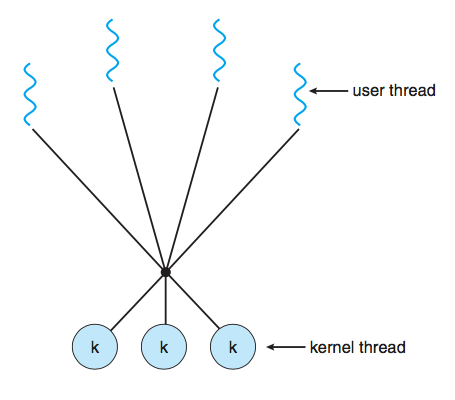
Many-to-One Model
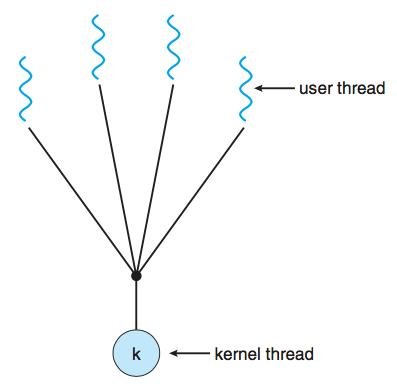
다대일 모델은 여러개의 user thread를 하나의 kernel thread로 관리하는 모델이다. thread library를 사용해서 관리하며 효율적인 방법이다. 그러나 하나의 thread가 block을 호출하면 나머지 thread도 block당하며 하나의 kernel thread를 사용하기 때문에 다중 코어 시스템에서의 병렬처리가 불가능하다.
One-to-One Model
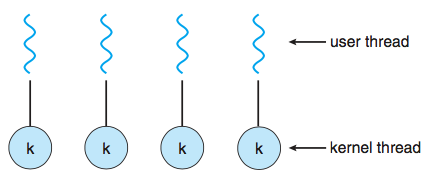
일대일 모델은 하나의 user thread를 하나의 kernel thread로 관리하는 모델이다. 이 모델은 동시성도 우수하고 다중 코어 시스템에서의 병렬처리도 가능하고 block에 독립적이기 때문에 빠르다. 다만 단점은 User thread가 많아짐으로서 kernel thread도 같이 많아지기 과부하가 걸리게 된다.
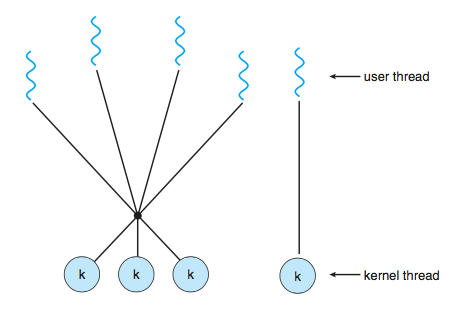
Many-to-Many Model
다대다 모델은 여러개의 user thread를 user thread의 수보가 적게 kernel thread로 관리하는 모델이다. 개발자는 필요한만큼의 사용자 스레드를 만들 수 있으며 해당 커널 스레드는 다중 프로세서에서 병렬로 실행할 수 있다. 또한 스레드가 블로킹 system call을 수행 할 때 커널은 다른 스레드의 실행을 예약 할 수 있다. 위의 모델들의 장단점이 분명하기 때문에 이 두가지 모델의 장점을 섞어서 만들어진 것이 two-level model이다.